Binary Classification Using Logistic Regression and MLP
Overview
This project, completed for the Statistical Learning for Data Science course, involved implementing Logistic Regression and a flexible Multi-Layer Perceptron (MLP) from scratch using Python and NumPy — without any deep learning framework. The goal was to deeply understand gradient-based optimization and the impact of architecture choices on classification performance.
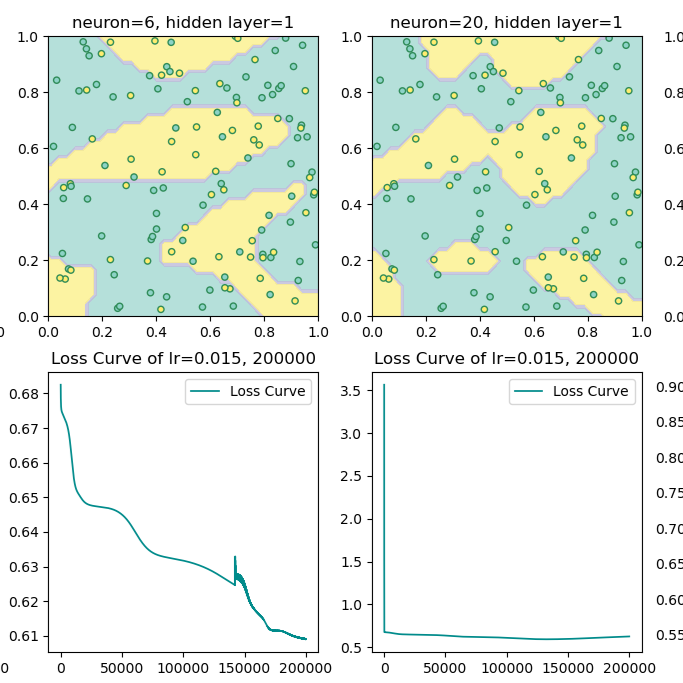
Results
Logistic Regression on synthetic binary dataset:
| Metric | Value |
|---|---|
| Precision | 0.9915 |
| Recall | 1.0000 |
| F1 Score | 0.9957 |
| Final Loss | 0.0180 |
MLP — Width Experiment (lr=0.025, epoch=250,000):
| Neurons per Layer | F1 Score | Final Loss |
|---|---|---|
| 3 | 0.5983 | 0.6342 |
| 6 | 0.7009 | 0.7484 |
| 20 | 0.8226 | 0.5845 |
| 50 | 0.9077 | 0.6618 |
MLP — Depth Experiment (lr=0.01, epoch=160,000):
| Layers | F1 Score | Final Loss |
|---|---|---|
| 2 | 0.9552 | 0.0346 |
| 3 | 0.9848 | 0.0127 |
| 6 | 0.9925 | 0.0043 |
| 10 | 1.0000 | 5.11e-06 |
Technical Details
- Logistic Regression:
- Forward pass: sigmoid activation on the linear combination of inputs.
- Loss: binary cross-entropy (with clipping for numerical stability).
- Optimization: vanilla gradient descent; weights and bias updated per iteration.
- MLP:
- Configurable layer sizes (e.g.,
[2, 20, 20, 1]for a 2-hidden-layer network). - Hidden layer activation: ReLU; output activation: sigmoid.
- Full backpropagation implemented manually via chain rule.
- Batch gradient descent; tolerance-based early stopping when loss reduction is negligible.
- Configurable layer sizes (e.g.,
- Dataset: Synthetic 2D binary classification datasets with controlled overlap; fixed random seeds for reproducibility.
- Evaluation: Precision, Recall, F1 score, and loss curves; decision boundary visualization with contour plots.
Challenges
- Vanishing gradients with deep networks: Observed that very deep networks sometimes failed to converge with sigmoid activations in hidden layers; resolved by switching hidden activations to ReLU.
- Learning rate sensitivity: High learning rates (e.g., lr=0.3) caused the loss to diverge rather than converge. Empirically tuned learning rates per architecture; recorded the number of iterations for loss to drop to 30% of its initial value as a diagnostic.
- Loss oscillation in MLP training: Unlike logistic regression, MLP loss sometimes fluctuated throughout training without reaching a clean plateau. Removing the tolerance-based early stopping and monitoring the full curve helped distinguish genuine convergence from oscillation.
Reflection and Insights
Implementing backpropagation by hand — rather than relying on autograd — forced a precise understanding of how gradients flow through a network and why architectural choices matter. The depth experiment aligned with theoretical expectations: deeper networks can represent more complex functions, but require careful learning rate selection and may suffer from instability. The width experiment confirmed that wider layers can compensate for shallower depth when the task requires capturing many parallel low-level features.
A particularly interesting observation was that in high-dimensional loss landscapes, saddle points become more common than local minima — meaning that with sufficient width, gradient descent rarely gets permanently stuck.
Team and Role
- Solo project: Both models fully implemented and analyzed independently.
Binary Classification Using Logistic Regression and MLP